
 当前位置:
当前位置: 
 顾问全程陪同指导让您无忧
顾问全程陪同指导让您无忧 免费看墓专车上门接送
免费看墓专车上门接送 购墓优惠折扣多还有赠品
购墓优惠折扣多还有赠品 殡葬一条龙让您省心省事
殡葬一条龙让您省心省事软阈值迭代算法(ISTA)和快速软阈值迭代算法(FISTA)
2024-09-09 13:15 作者:佚名
缺月挂疏桐,漏断人初静。
谁见幽人独往来,缥缈孤鸿影。
惊起却回头,有恨无人省。
拣尽寒枝不肯栖,寂寞沙洲冷。---- 苏轼
更多精彩内容请关注微信公众号 “优化与算法”
ISTA算法和FISTA算法是求解线性逆问题的经典方法,隶属于梯度类算法,也常用于压缩感知重构算法中,隶属于梯度类算法,这次将这2中算法原理做简单分析,并给出matlab仿真实验,通过实验结果来验证算法性能。
对于一个基本的线性逆问题:
其中\({\bf{A }} \in {^{M imes N}}\), \({\bf{y }} \in {^{M}}\)且是已知的,\(\bf{w}\)是未知噪声。
(1)式可用最小二乘法(Least Squares)来求解:
当 \(M=N\) 且 \(\bf{A}\) 非奇异时,最小二乘法的解等价于\(\bf{A^{-1}y}\)。
然而,在很多情况下,\(\bf(A)\) 是病态的(ill-conditioned),此时,用最小二乘法求解时,系统微小的扰动都会导致结果差别很大,可谓失之毫厘谬以千里,因此最小二乘法不适用于求解病态方程。
什么是条件数?矩阵 \(\bf{A}\) 的条件数是指 \(\bf{A}\) 的最大奇异值与最小奇异值的比值,显然条件数最小为1,条件数越小说明矩阵越趋于“良态”,条件数越大,矩阵越趋于奇异,从而趋于“病态”。
为了求解病态线性系统的逆问题,前苏联科学家安德烈·尼古拉耶维奇·吉洪诺夫提出了吉洪诺夫正则化方法(Tikhonov regularization),该方法也称为“岭回归”。最小二乘是一种无偏估计方法(保真度很好),如果系统是病态的,则会导致其估计方差很大(对扰动很敏感),吉洪诺夫正则化方法的主要思想是以可容忍的微小偏差来换取估计的良好效果,实现方差和偏差的一个trade-off。吉洪诺夫正则化求解病态问题可以表示为:
其中\(\lambda>0\) 为正则化参数。问题(3)的解等价于如下岭回归估计器:
安德烈·尼古拉耶维奇·蒂霍诺夫(俄文:阿尔瓦勒德普列耶娃;1906年10月17日至1993年10月7日)是苏联和俄罗斯数学家和地球物理学家,以对拓扑学、泛函分析、数学物理和不适定问题的重要贡献而闻名。他也是地球物理学中大地电磁法的发明者之一。

岭回归是采用 \({\ell _2}\) 范数作为正则项,另一种求解式(1)的方法是采用 \({\ell _1}\) 范数作为正则项,这就是经典的LASSO(Least absolute shrinkage and selection operator)问题:
采用 \({\ell _1}\) 范数正则项相对于 \({\ell _2}\) 范数正则项有两个优势,第一个优势是 \({\ell _1}\) 范数正则项能产生稀疏解,第二个优势是其具有对异常值不敏感的特性,这一点恰好与岭回归相反。
式(5)中的问题是一个凸优化问题,通常可以转化为二阶锥规划(second order cone programming)问题,从而使用内点法(interior point)等方法求解。然而在大规模问题中,由于数据维度太大,而内点法的算法复杂度为 \(O({N^3})\),导致求解非常耗时。
基于上述原因,很多研究者研究通过简单的基于梯度的方法来求解(5)式。基于梯度的方法其计算量主要集中在矩阵 \(\bf{A}\) 与向量 \(\bf{y}\) 的乘积上,算法复杂度小,而且算法结构简单,容易操作。
在众多基于梯度的算法中,迭代收缩阈值算法(Iterative Shrinkage Thresholding Algorithm)是一种非常受关注的算法,ISTA算法在每一次迭代中通过一个收缩/软阈值操作来更新 \(\bf{x}\),其具体迭代格式如下:
其中 \({{\mathop{\rm soft} olimits} _{\lambda t}}( \cdot )\) 是软阈值操作函数:
软阈值操作函数如下图所示:
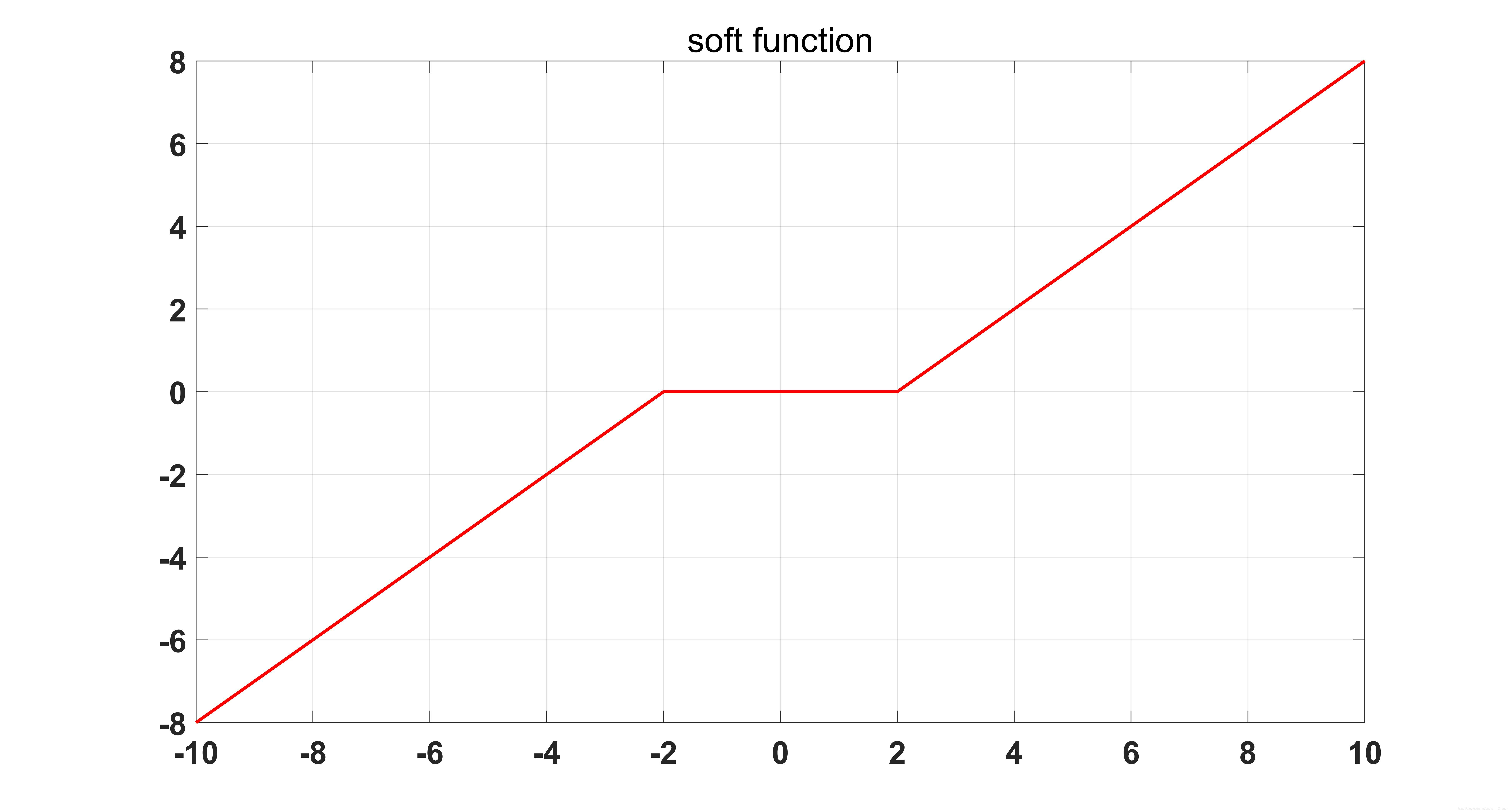
其中 \(sign()\) 是符号函数。
那么ISTA的迭代格式(6)式是怎么来的呢?算法中的“收缩阈值”体现在哪里?这要从梯度下降法(Gradient Descent)说起。
考虑一个连续可导的无约束最小化问题:
(8)式可用梯度下降法来求解:
这里 \(t_k>0\) 是迭代步长。我们知道,梯度下降法可以表示成 \(f\) 在点 \(x_{k-1}\) 处的近端正则化(proximal regularization),其等价形式可以表示为:
(9)-(10)可由李普希兹连续条件 \({\left\| { abla f({{\bf{x}}_k}) - abla f({{\bf{x}}_{k - 1}})} \right\|_2} \le L(f){\left\| {{{\bf{x}}_k} - {{\bf{x}}_{k - 1}}} \right\|_2}\) 和 \(f\) 在 \(x_{k-1}\) 处的2阶泰勒展开得到,很简单,这里不再赘述。
将(8)式加上 \({\ell _1}\) 范数正则项,得到:
则(10)式相应变成:
时(12)忽略掉常数项 \(f(\bf x_{k-1})\) 和 \({ abla f({{\bf{x}}_{k - 1}})}\) 之后,(12)式可以写成:
文献中已经证明,当迭代步长取 \(f\) 的李普希兹常数的倒数(即 \({1 \over {L(f)}}\))时,由ISTA算法生成的序列 \(\bf x_k\) 的收敛速度为 \(O({1 \over {\rm{k}}})\) ,显然为次线性收敛速度。
ISTA算法的伪代码见原文,matlab代码如下:
实际过程中,矩阵 \(\bf A\) 通常很大,计算其李普希兹常数非常困难,因此出现了ISTA算法的Backtracking版本,通过不断收缩迭代步长的策略使其收敛。
为了加速ISTA算法的收敛,文献中作者采用了著名的梯度加速策略Nesterov加速技术,使得ISTA算法的收敛速度从 \(O({1 \over {\rm{k}}})\) 变成 \(O({1 \over {\rm{k^2}}})\)。具体的证明过程可参见原文的定理4.1。
FISTA与ISTA算法相比,仅仅多了个Nesterov加速步骤,以极少的额外计算量大幅提高了算法的收敛速度。而且不仅在FISTA算法中,在几乎所有与梯度有关的算法中,Nesterov加速技术都可以使用。那Nesterov加速技术为何如此神通广大呢?
Nesterov加速技术由大神Yurii Nesterov于1983年提出来的,它与目前深度学习中用到的经典的动量方法(Momentum method)很相似,和动量方法的区别在于二者用到了不同点的梯度,动量方法采用的是上一步迭代点的梯度,而Nesterov方法则采用从上一步迭代点处朝前走一步处的梯度。具体对比如下。
动量方法:
Nesterov方法:
对比可发现,Nesterov方法和动量方法几乎一样,只是梯度处稍有差别。下图能更直观看出二者的区别。
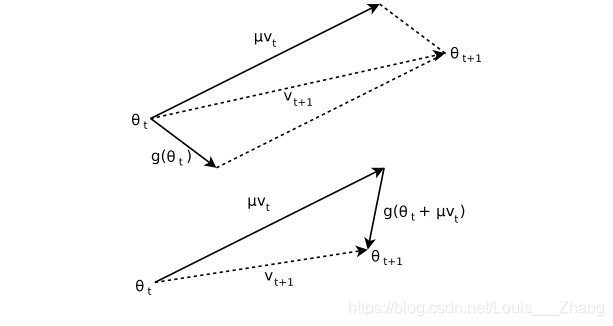
尤里·内斯特罗夫是俄罗斯数学家,国际公认的凸优化专家,特别是在高效算法开发和数值优化分析方面。他现在是卢旺大学的教授。

FISTA算法的伪代码见原文,matlab代码如下:
为了验证ISTA算法和FISTA算法的算法性能,此处用一维随机高斯信号做实验,测试程序如下:
仿真结果图如下所示:
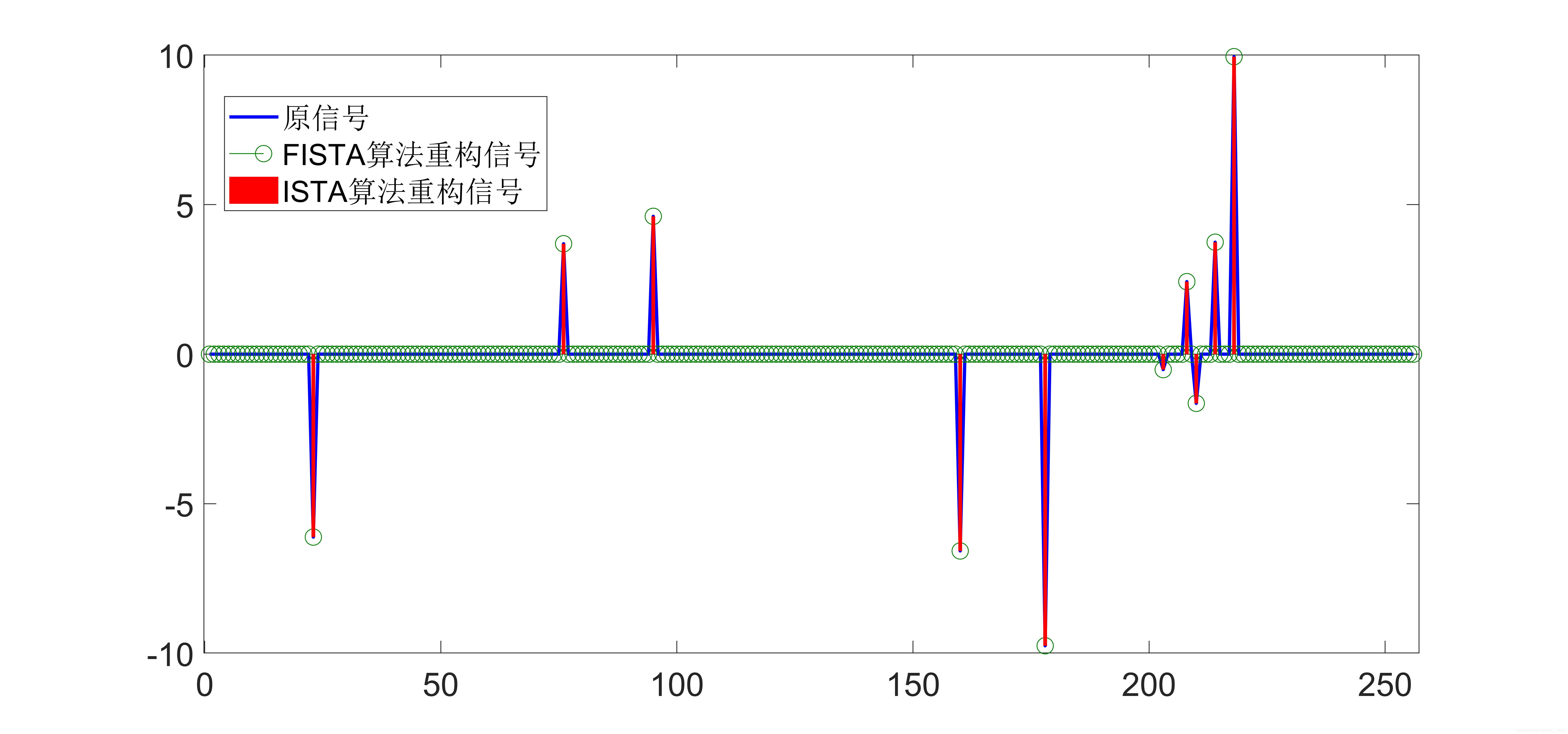
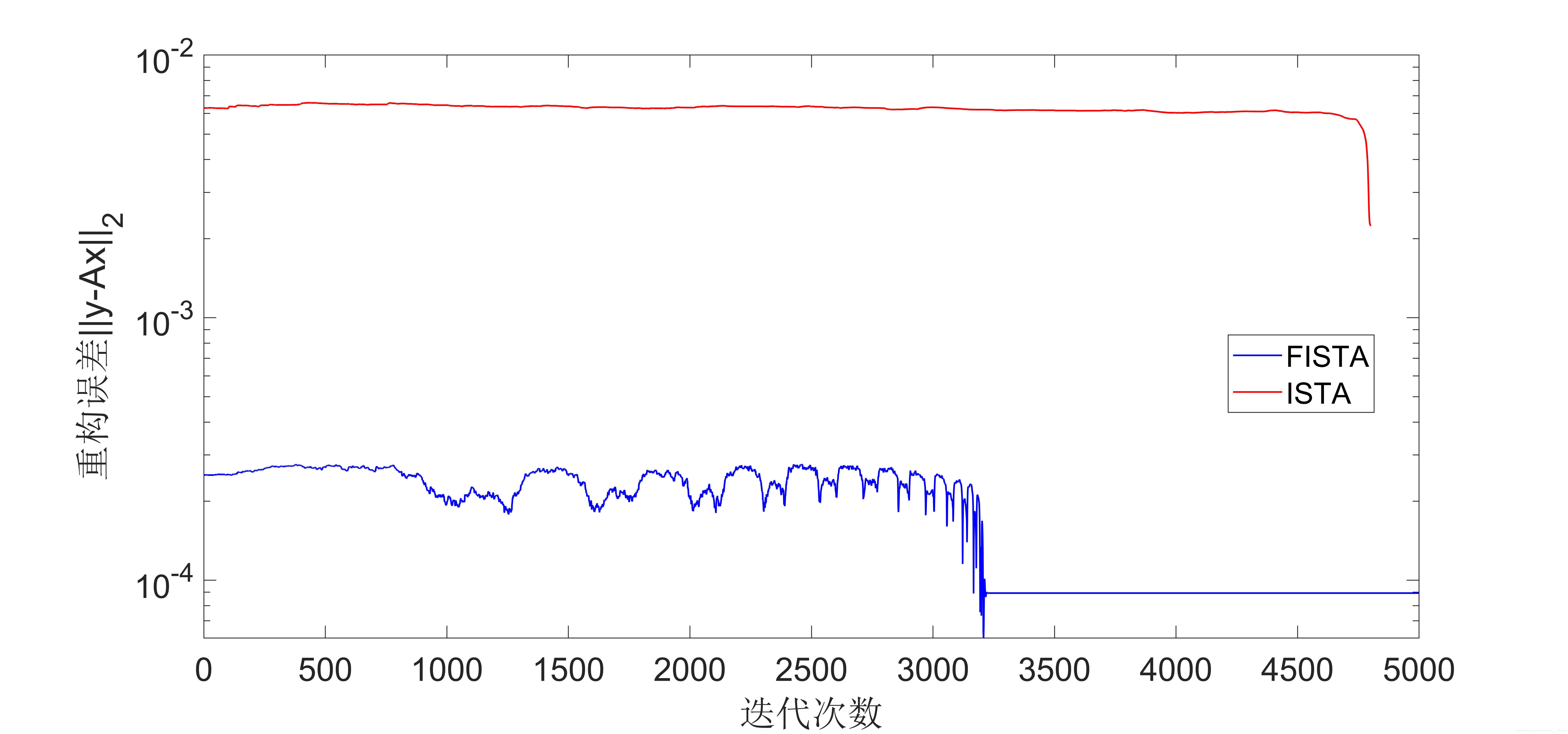
从实验结果可以看出,FIST算法收敛速度比ISTA算法要快很多。
这里顺便贴上原文中实验图,是关于图像去噪的:


图示为迭代次数与去噪效果的直观图,左边为FISTA算法,右边为ISTA算法,可以明显发现FISTA算法去噪速度较快。
Iterative Shrinkage Thresholding 实际上不能称为一种算法,而是一类算法,ISTA算法和FISTA以及ISTA的改进算法如TWISTA算法等都是采用软阈值操作,求解的是 \({\ell _1}\) 范数正则化问题(LASSO),而还有一些算法是采用硬阈值操作的,这类算法称为迭代硬阈值类算法(Iterative Hard Thresholding),这类算法求解的问题是 \({\ell _0}\) 约束的最小化问题,是个非凸优化问题,以后有机会总结一下迭代硬阈值类算法。
[1] Beck, Amir, and Marc Teboulle. "A fast iterative shrinkage-thresholding algorithm for linear inverse problems." SIAM journal on imaging sciences 2.1 (2009): 183-202.
[2] Yurii E Nesterov., Dokl, akad. nauk Sssr. " A method for solving the convex programming problem with convergence rate O (1/k^ 2)" 1983.
更多精彩内容请关注微信公众号 “优化与算法”

 真实优惠
真实优惠 信息全面
信息全面 专业服务
专业服务 万千口碑
万千口碑 诚信经营
诚信经营 广东墓地网手机站
广东墓地网手机站 天猫官方旗舰店
天猫官方旗舰店 020-88888888
020-88888888
